The Shannon-Fano compression algorithm first examines all elements of the text (or binary data) to be compressed and counts their frequency in the source. It then sorts the actual symbols contained in the source by descending frequency, so that the most common element will be at the left and the least common one at the right. It then segments the list into two sections such that the sum of the number of occurrences of elements to the left is as close to the sum of occurrences of the elements to the right as possible. A 0 is then assigned to the left section, and a 1 to the right section, and the algorithm recursively continues splitting and assigning a value until no further split is possible. In this way, each input element will be assigned a sequence of 0/1 values - and thus a binary encoding. The source data is then compressed by replacing each element of the source with its binary encoding, which will typically have a far shorter length (at least, for the more common elements) than the usual 8 bit encoding.
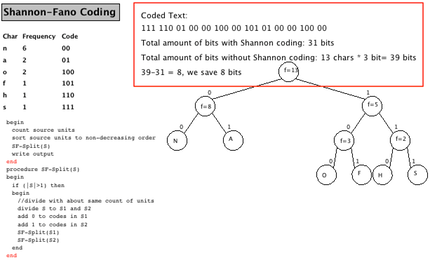
In the generator, the user can specify a string to be encoded; the default string to be encoded is "shannonfannon", where it is obvious that "n" is the most common character (6 occurrences), followed by "a" and "o" with two occurrences each, and the other characters ("s", "h", "f") with one occurrence each.
The algorithm starts with a verbal description of the algorithm, as shown below.

In the next step, the process of segmenting the elements into two halves and assigning a bit value, and the further segmenting elements. At the time of the screenshot, "N", "A", "O" and "F" have already been assigned a final code, and the process has to continue for "H" and "S".

The animation ends with the final encoding for each input character, as shown in the table to the left in column "Code", and also visible in the tree. It also provides the Shannon-Fano encoding of the source and gives a rough approximation of the space saved (highlighted here with a red box which is not part of the actual animation).